A Toolbox for Maintainable Software

Introduction and Motivation
Writing and launching a new project is easy. Making what appeared to be a minor change to long-running system can often be a nightmare. In this article we discuss two techniques (dependency inversion and dependency injection) we can add to our toolbox to help build maintainable software. We then introduce a a theory on what design decisions lead to hard-to-maintain software.
Dependency Inversion
Dependency inversion is a technique we can use to loosely couple the classes we write. This makes it easier to make changes to one class without breaking the classes that depend on it. Let’s look at a simple sample of code and how we can invert its dependencies.
Imagine you are an engineer on the hot new startup UberEatsOrGrubHub.com which can definitively tell its users whether they should order a meal through Uber Eats or GrubHub. Wow. The software asks a user for the name of a food and the restaurant to order it from and picks the one that offers it at the lowest price. This is a contrived example but we are trying to keep things simple.
It turns out Uber Eats is pretty transparent and allows clients to make simple HTTP requests in order to get the price for a [food, restaurant] combo, so we create a simple UberHttpApi class.

Simple wrapper for getting prices from the Uber HTTP API.
GrubHub on the other hand is opaque and doesn’t want nosey start ups easily getting access to its pricing structure. Another team at our start up had to write a complicated web scraper to periodically poll prices from GrubHub. The team puts the results in a JDBC database that our start up owns, so we create a simple class to query prices from the database.

Simple class for querying prices from the database of scraped GrubHub prices.
Now that we have our backends all lined up, its time to get the requirements from our business partners. They performed extensive market research and have determined that users want to have our software recommend the service with (drumroll) the lowest price, so we create a class to express the business logic.

Business logic to get the GrubHub and Uber Eats prices and select the lowest one.
Something has to run the code so we wrap it all up in a Main class and call it a day. Time to ship our flagship project!
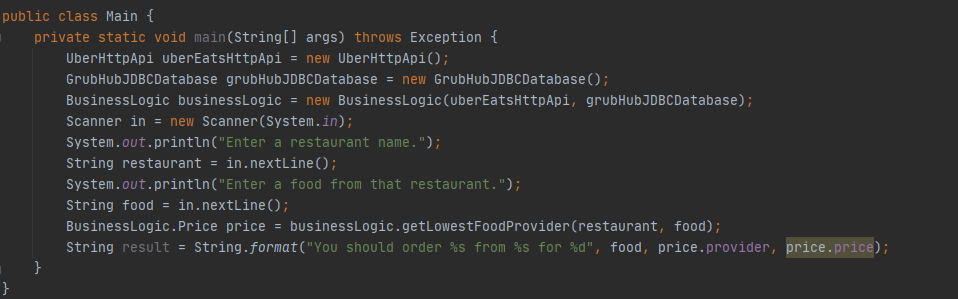
Main class that runs everything.
If we were to diagram the relationships between these classes, we would get the following.
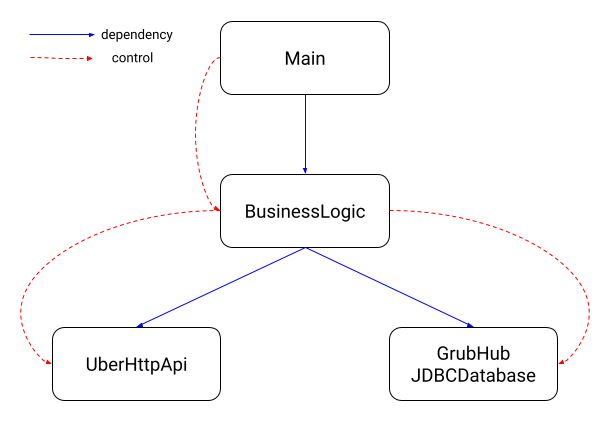
The blue lines denote a dependency, for example, Main depends on BusinessLogic because Main has an import statement for BusinessLogic (technically Main depends on the other two classes but let me hand wave for a bit). The red lines denote the flow of control, for example, Main calls the getLowestFoodProvider() method so Main controls the flow of execution to Business logic.
At this point, BusinessLogic is tightly coupled with its dependencies: UberHttpApi and GrubHubJDBCDatabase. If we make changes to either one, we will need to recompile the unit (i.e., JAR) that BusinessLogic is a part of. We run the risk of breaking the BusinessLogic class or worse, breaking it in a way that is not covered by a test. What is worse, the implementation details of the two classes bled into BusinessLogic; BusinessLogic has to know how to construct a SQL query and an HTTP URL in order to get the prices it needs. If big changes come our way, business logic will need to get updated too. This is not monumental in this example; we are talking about four Java classes that are 20 lines of code each. But when we move to a large code base with lots of dependencies, these kind of design issues can get expensive.
We can use dependency inversion to make the dependencies between these classes more maintainable. Dependency inversion will allow us to, for example, keep the flow of control the way it is, but flip dependencies so that BusinessLogic does not directly depend on either UberHttpApi or GrubHubJDBCDatabase. To do this, we will create an interface for UberHttpApi and for GrubHubJDBCDatabase to implement and we will have BusinessLogic refer to those instead. Lets take a look at the new code and the result it has on the dependencies and flow of control.

An interface for getting a price given a restaurant and food name.
There are several interfaces we could cook up to help out the BusinessLogic class. In this example, we notice that both the UberHttpApi and GrubHubJDBCDatabase classes return a price. We also notice they require the client to understand the underlying implementation and build either a query or a URL. Both classes can help the client by instead taking the restaurant and food themselves which abstracts away what technology is used under the hood from the client.
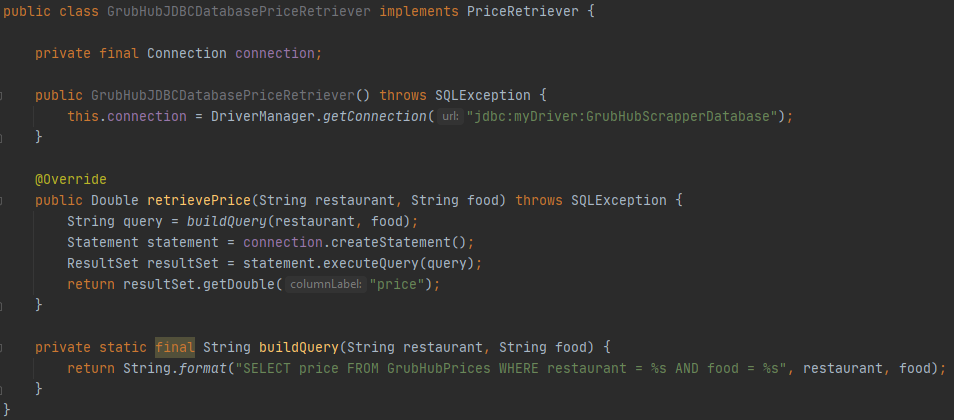
An implementation of PriceRetriever that uses a JDBC database under the hood to get GrubHub prices.
This is similar to the GrubHubJDBCDatabase class before. Note that the logic to build the query is now tucked away inside of a private method. Otherwise the steps to query the database are in tact.

An implementation of PriceRetriever that uses an HTTP call under the hood to get Uber Eats prices.
This is similar to the UberEatsHttpApi class before. Note that the logic to build the URL is now tucked away inside of a private method. Otherwise the steps to send a HTTP request are in tact.
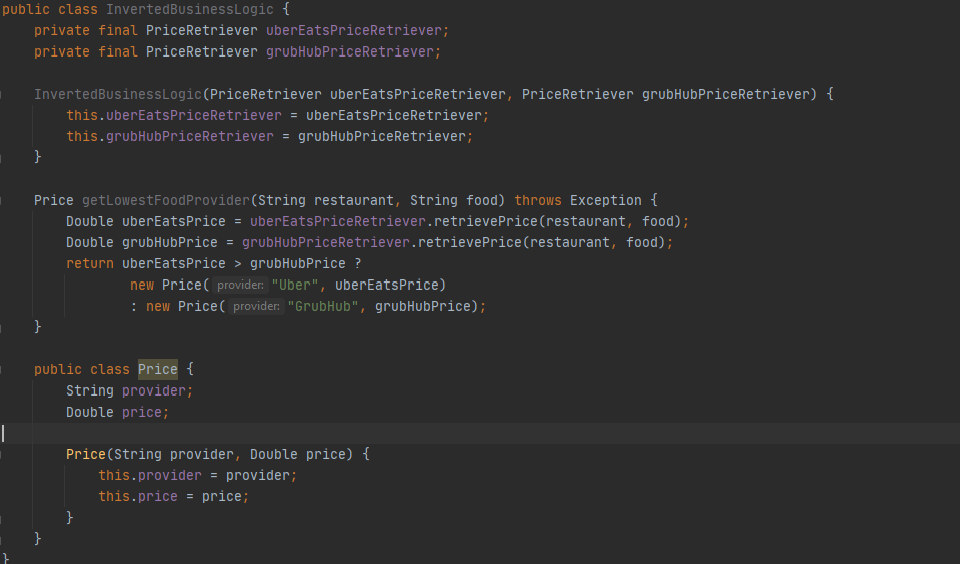
A rewrite of the BusinessLogic class using the PriceRetriever interface.
Now we can rewrite BusinessLogic using the new PriceRetriever interface. Notice how much more concise the class is. It no longer needs to build URLs or SQL queries. It no longer references classes that call out the name of the technologies they use under the hood. The class is focused just on the business logic. While the “logic” in this example is super-simple, in a much more complex piece of business logic, this clarity is even more helpful. More importantly, we can change the implementation details of the price retrievers without having to touch this class or its tests.
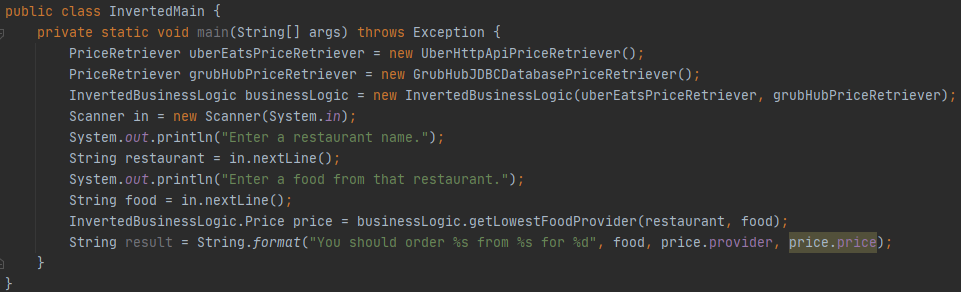
A rewrite of the Main class using the InvertedBusinessLogic and PriceRetrievers.
We also need to rewrite the Main class. It needs to use the new InvertedBusinessLogic and the new PriceRetrievers. This creates a dependence for Main on the PriceRetriever implementations which is not great but we are going to hand wave out of the diagram we show. We will present a technique for avoiding compile time dependencies from Main to implementation details later in the Dependency Injection section.
Now we can recreate the dependency and flow of control diagram.
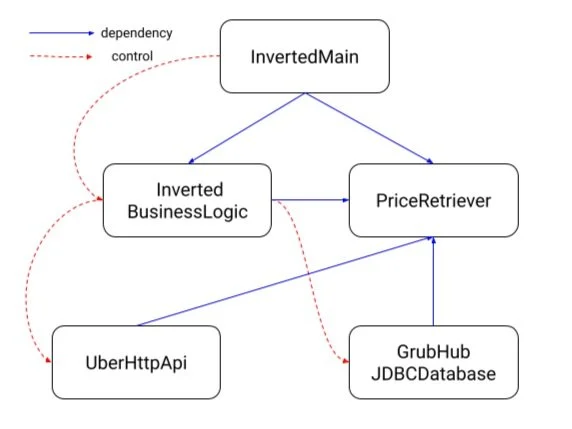
While this looks more complicated it has some nice properties over the previous setup. The business logic no longer depends on our API or data base code. This is nice because now they act more like plugins; changes to the business logic (which should be easy to change) should not have the added complication of redeploying our API or data base projects. This makes migrations much easier; if we need to migrate off of JDBC because it is having trouble scaling, the business logic is not affected at all; that was not the case before.
InvertedMain’s dependency on the business logic is a bit unfortunate, but its something we can address with dependency injection discussed below.
Dependency Injection
In the previous example, the Main class had to manually create the dependencies for InvertedBusinessLogic and then manually create an instance of InvertedBusinessLogic. Our goal is to make the non-business logic related details plugins to the business logic. Dependency injection is a tool that lets us do just that. It organizes our components and their dependencies in one place and makes swapping between different implementations of our interfaces easy. Additionally, it helps improve our unit tests which we will talk about at the end of this section.
To begin explaining what dependency injection is, we will use it to rejigger the Main to use dependency injection and then highlight the nice properties it has. In this example, we will use the Guice dependency framework, but there are several popular options to choose from, like Spring.
public class InvertedInjectedMain { private static void main(String[] args) throws Exception { InvertedInjectedBusinessLogic businessLogic = Guice.createInjector(new BusinessLogicModule()).getInstance(InvertedInjectedBusinessLogic.class); Scanner in = new Scanner(System.in); System.out.println("Enter a restaurant name."); String restaurant = in.nextLine(); System.out.println("Enter a food from that restaurant."); String food = in.nextLine(); Price price = businessLogic.getLowestFoodProvider(restaurant, food); String result = String.format("You should order %s from %s for %d.", food, price.provider, price.price); }
Lets start at the top by rewriting the main class. Instead of manually creating the business logic class and its dependencies, we just use Guice to create one for us. All the details about how to make a business logic class and what dependencies its needs for its constructor are in the BusinessLogicModule class, so lets look at that next.public class BusinessLogicModule extends AbstractModule { @Override protected void configure() { bind(PriceRetriever.class) .annotatedWith(UberEatsPriceRetriever.class) .to(UberHttpApiPriceRetriever.class); bind(PriceRetriever.class) .annotatedWith(GrubHubPriceRetriever.class) .to(GrubHubJDBCDatabasePriceRetriever.class); } @BindingAnnotation @Target({FIELD, PARAMETER, METHOD}) @Retention(RUNTIME) public @interface UberEatsPriceRetriever {} @BindingAnnotation @Target({FIELD, PARAMETER, METHOD}) @Retention(RUNTIME) public @interface GrubHubJDBCDatasetPriceRetriever {} }
This class is used to specify which classes should be created whenever Guice is asked to create a class whose constructors have dependencies. We are just focused on the business logic class which has two price retrievers it needs. The bind() method means that any time a PriceRetriever class that has the UberEatsPriceRetriever annotation is needed, Guice will call the constructor for UberHttpApiPriceRetriever. This process could be recursive if either of the price retrievers’ constructors had dependencies.
public class InvertedInjectedBusinessLogic { private final PriceRetriever uberEatsPriceRetriever; private final PriceRetriever grubHubPriceRetriever; @Inject InvertedInjectedBusinessLogic( @UberEatsPriceRetriever PriceRetriever uberEatsPriceRetriever, @GrubHubPriceRetriever PriceRetriever grubHubPriceRetriever) { this.uberEatsPriceRetriever = uberEatsPriceRetriever; this.grubHubPriceRetriever = grubHubPriceRetriever; } Price getLowestFoodProvider(String restaurant, String food) throws Exception { Double uberEatsPrice = uberEatsPriceRetriever.retrievePrice(restaurant, food); Double grubHubPrice = grubHubPriceRetriever.retrievePrice(restaurant, food); return uberEatssPrice > grubHubPrice ? new Price("Uber", uberEatsPrice) : new Price("GrubHub", grubHubPrice); } public class Price { String provider; Double price; Price(String provider, Double price) { this.provider = provider; this.price = price; } } }
This is the last main thing we need to explain to bring it all together; changing the business logic class. We add the @UberEatsPriceRetriever annotation to the Uber Eats price retriever dependency and the @GrubHubPriceRetriever annotation to the GrubHub price retriever. This ties back to the annotations called out in the module.
Now we can unpack this cryptic line in the main class.
InvertedInjectedBusinessLogic businessLogic = Guice.createInjector(new BusinessLogicModule()).getInstance(InvertedInjectedBusinessLogic.class);
We first act Guice to create an injector, which takes modules as input so that Guice can know how to resolve dependencies. We pass in a new instance of the BusinessLogicModule() which is configured to bind PriceRetrievers based on their annotations. We then use the injector to get an instance of the InvertedInjectedBusinessLogic class. This means that Guice make a call to InvertedInjectedBusinessLogic’s constructor, where it will first notice that it needs a PriceRetriever that happens to be annotated with a @UberEatsPriceRetriever annotation. The module tells it that such cases should use a UberHttpApiPriceRetriever. Guice notices this class has a no argument constructor and calls it. The same process follows for the other price retriever. Notice that these dependencies are resolved at runtime and not compile time.
This means that we can configure our dependencies such that compile time dependencies follow the stability principle but at runtime the technology dependent price retrievers will execute.
Additionally, by injecting dependencies, we end up writing our code in a way that all of a class’ dependencies are explicitly listed in its constructor, and those dependencies typically refer to interfaces. This means that in tests it is easy to insert mocks or test versions of the dependencies so that we can precisely control the behavior of the class under test.
Stability Principle
Code that is expected to change often should be easy to change. In our example, the business logic should be the easiest thing to change. Business partners will want to experiment with it all the time, testing out small changes over and over that try to drive value, increase revenue, make customer happy, etc. In this section, we describe a principle defined in Clean Architecture, that helps us design our software so that the likely-to-change modules are in fact easy to modify.
“Unstable components should only contain the software that is volatile - software that we want to be able to quickly and easily change.”
The key to making things easy to changes lies in how we structure the dependencies between our components. There are two dimensions we can use to describe the dependencies of a component: stability and independence.
Stability refers to how difficult it is to make changes to a component. A highly stable component requires a large effort to change. A highly instable component requires little effort to change. Stability of a component is simply measured by the number of other components that depend on it.
Independence refers to how much we would expect a component to need to get changed because of changes to other components. A highly independent component is not expected to change often as other components in the project change. A highly dependent component is expected to change often as other components it depends on change. A highly independent component is not expected to change when other components in the project change. Independence of a component is simply measured by the number of components it depends on.

The four types of components based on stability and independence.
A stable independent component has many other components depending on it but it depends on few to no other components. It is difficult to change but is unlikely to need to be changed as a result of other changes in the system.
An unstable dependent component has few to no components depending on it but it depends on many other components. It is easy to change and is likely to need to be changed as a result of other changes in the system.
A stable dependent component has many other components depending on it and it depends on many other components. It is difficult to change and it is likely to need to be changed as a result of other changes in the system. Why would we make something like this?
An unstable independent component has few to no components depending on it and depends on few to no other components. It is easy to change and unlikely to need to be changed because of other changes in the system.
What do we mean when we say something is “hard to change?” Stable components have many dependencies which could mean:
we need to run the tests of not just the stable component, but all of its dependencies, and their dependencies, and so on
if our unit/integration tests are not airtight, there is a higher likelihood we break something in any of the ancestor dependencies
depending on how how these components are packaged into deployable units (exe, jar, etc.) we may need to redeploy dependent components
To avoid these issues, we want to avoid creating stable components that we want to be flexible and easy to change (i.e., business logic). We can use the dependency injection and inversion techniques described to achieve this. They enable us to reroute dependencies and make implementation details like APIs and Databases plugins that are easy to change. This is great because APIs and Databases will be subject to rewrites and migrations and we want to insulate the business logic from them as much as possible.