A Short, Cherry-picked History of AI

IBM’s Deep Blue AI beat its first Chess world champion in 1997.
I recently gave a talk at UCI to a group of talented high schoolers in the BEAM program. These students are eager to understand the role AI might play in the tech industry when they graduate from college 4-6 years from now. They are worried about signing up for college degrees that will get wiped out by the time they graduate college. I gave a presentation on the history of AI because I think there are some helpful parallels between what is happening today and several AI breakthroughs in the past: e.g., they often overpromises; they solves narrow problems that are difficult to scale; eventually they always lead to a lasting change. Below is my summary of that talk since it was not recorded.
What is AI?
Before I start, I want to discuss what Artificial Intelligence is? As we will cover later, the term was coined ahead of the 1956 Dartmouth Workshop as a marketing tool to drum up interest from a wide range of researchers (we will see this pattern play out many times where AI can’t help but create its own hype). As a result, the term AI is used to refer to a lot of different things.
When I took an AI class with Professor Shelton he started by explaining the term AI with a quote from Dijkstra (which I incorrectly attributed to Turing in the presentation). Dijkstra ponders the question question of whether or not computers are or can think, to which he responds:
“The question is just as relevant and just as meaningful as the question whether submarines can swim.”
I like using this quote to frame my thinking about what is and what is not AI. It implies that it is not important whether or not the machine (submarine) is a thinking/conscious entity like a human, it just matters that the machine is getting the job done (moving through water). This is nice because it means what we are really talking about is automation, not just AI. We have an even richer history of automation to pull from to understand our current predicament with AI or more specifically with powerful generative AI models like LLMs.
Throughout the talk I tried to show that in each advancement of AI, the underlying algorithm is not really thinking, but it is getting a specific job done and the same is true with LLMs today. I also tried to make the argument that AI is a lot like magic (another Professor Shelton quote); once one understands how the AI (trick) is performed, it no longer seems like its actually AI (magic).
1912 - Autopilot
Since we are talking about the larger theme of automation, I started with the creation of aircraft autopilot. This technology automated some parts of an aircraft’s flight and was introduced in 1912 by Lawrence Sperry. It did not use a digital computer; they did not exist. It used a gyroscope and hydraulics to keep the airplane flying in a straight compass direction. I polled the students. Is it artificial intelligence? Is it thinking? About two students raised their hands. But does it matter? It does not. It automates the task at hand.
I like to highlight autopilot for two reasons. First, while the technology debuted in 1912, it took a very long time until it became as sophisticated as it is today. Second, despite being over 100 years old, this technology has not replaced pilots. Why is that? Students raise some good points. The severity of the autopilot making a mistake is measured in hundreds of lives of passengers. Pilots need years of specialized training to be effective. When a problem occurs, is often a unique situation which requires critical thinking under pressure. I like to think of airplane pilot as a career with automation-resilient properties. Later we will compare it to a career that is not.
1951 - Game AI
Around 1951, there were many research projects that successfully solved different types of games, like chess and checkers. This is where many textbooks like to start the history of AI.
The first chess playing AI was developed in 1951 by Dietrich Prinz but it was very limited. It could only solve “mate-in-two” problems, i.e., it could only solve the game if a solution existed in the next two moves. It only took seven more years for Alex Bernstein to create the first AI capable of playing an entire game of chess in 1958. However, it had to run on a large IBM 704 mainframe as it was the only machine powerful enough to perform all the calculations needed. In 1958 one of these machines cost $2 million dollars, which would be $22 million dollars adjusted for inflation today. This is a common parallel in AI’s history: using extraordinary compute resources to solve not so critical problems.
It is worth noting another parallel shared by Chess AI and autopilot. While they both came out a long time ago, it took them both a long time to achieve excellence; it was not until 1997 that IBM’s Deep Blue AI was able to finally beat a world champion at chess.
Was this AI? Was the IBM 703 thinking? I get a couple more hands raised by students than I did for autopilot. Again it doesn’t matter. It was able to beat novices at a game of chess. Under the hood, the computer was creating a graph of all possible chess games (for a more details I like Baeldung’s article). The first node in the graph represented the opening chess board with no pieces moved. From that node we create a new node for each of the 20 possible first moves that white can make and connect those nodes to the first node with an edge. We do this recursively until we constructed all possible game states; the diagram below shows an example of what some of the nodes in this graph would look like.
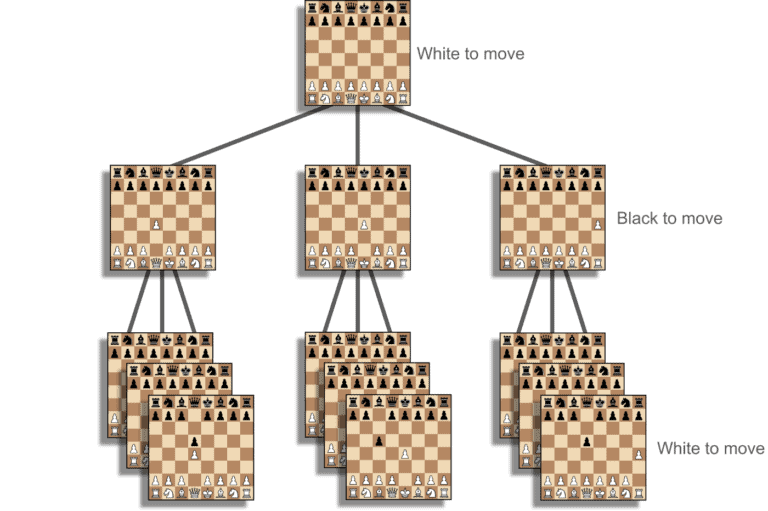
A small snippet of all the possible moves players in chess can make connected in a graph.
We work backwards from the nodes that represent the end of the game and we assign a weight to each edge that indicates how many paths ahead will result in a win or a loss. We have the machine pick edges with the highest probability to win (maybe we average the win percentages of all the paths ahead). This would be a simple brute force approach to implement. But there is a big problem with it; there are an estimated 10^120 possible games of chess. This is an enormous number and not one that we could ever fit into memory on a computer, not even if we used all the computers on the planet. To deal with that limitation, researchers like Bernstein and Prinz had to apply heuristics and optimizations based on specific knowledge about chess in order to optimize the code and loading all 10^120 possible games at once. That kind of optimization took 7 years (assuming Bernstein started in 1951) and only applied to chess. Thus starts AI’s history of being expensive to solve a single problem without scaling.
Here we see another parallel in AI breakthroughs. They often apply to narrow, complicated problems and are difficult or time intensive to scale to other domains.
1956 - The Dartmouth Workshop
The Dartmouth Workshop is considered by many to be the event that kicked artificial intelligence off as a research field. John McCarthy coined the term “artificial intelligence” and invited several researchers to attend the workshop where he encouraged them to develop research and publish papers in this field. The workshop was a success. It kicked off a big wave of research in this new space. It popularized the term “artificial intelligence”.
Many successful research papers stemmed from this workshop. Once again though, they showed how artificial intelligence could solve several problems that were both complicated but narrow in scope. For Example, one paper showed a technique, called STUDENT, that solved high school algebra word problems.
As the number of successful applications of artificial intelligence grew, so did they hype for what they would do next. For example, Herbert Simon said, “machines will be capable, within twenty years, of doing any work a man can do.” Companies and institutions gobbled the hype up. For example, DARPA and the British Science Research Council, started investing serious money into artificial intelligence. Here we see another parallel in AI breakthroughs: they tend to overpromise what they will deliver in the future.
1973 - The Lighthill Report
Nearly 20 years after the Dartmouth Workshop many of the big promises of AI had not panned out like Mr. Simon and others predicted. The British Research Council asked Mr. Lighthilll to write a report on all the research they had helped to fund for artificial intelligence. The report was critical of artificial intelligence’s ability to scale to solve more practical problems. For example, the STUDENT example above used heuristic rules specific to algebra and word problems written in English. The only way to scale it to geometry or English or formulas would be to spend the same amount of effort developing another set of heuristic rules just for each of those domains. This is prohibitively expensive.
This was was the start of a larger disillusionment with artificial intelligence that led to a large decrease in funding and interest for artificial intelligence research.
1978 - Phone Operators
In 1950, there were 1.3 million switchboard operators in the United States. By 1978, automated switching technology had fully rolled out and the phone operator job was largely eliminated.
Automated switching technology is the low on the list of things people would consider AI, but as we said above, even if it is not actually thinking it does get the job done. I highlight this particular job that was automated away because it contrasts so well with the job of pilot.
I asked the students why it might be that phone operator jobs were wiped out while airplane pilots persisted? They had good responses. It was an easily automated task that did not require problem solving. The impact of incorrectly routing a phone call was low. The cost of what the phone operator did was low to the impact of their job.
When we try to guess what is going what impact artificial intelligence will have on certain jobs, it is helpful to think if that job is more like phone operators or more like pilots.
1980 - Expert Systems
An expert system is a type of AI that relies on many rules, e.g., what you would see in IF statements in programming. Expert systems were popularly used to help doctors diagnose illnesses. Developers would work with many medical experts to compile every possible rule they would need to know to diagnose patients on a wide array of illnesses. For example, if temperature > 103 and throatIsSore == then diagnose(strepThroat).
Doctors would use a computer running an expert system and enter in all the readings from the patient into it, e.g., temperature, presence of a headache, etc. The system would perform an algorithm which processed all of these rules, which were ranked, in order to pick the best diagnosis. These systems could rely on tens of thousands of rules, if not more.
Expert systems were met with initial commercial success as companies tried to mimic the success of a company called DEC. DEC used an R1 system in order to simplify the buying process for their large and complex VAX computer systems (a narrow and complex problem). The company estimated that it saved $25M annualy. Many large companies began pouring money into developing their own expert systems to boost their own sales numbers. This led to large boons for companies like Apple and IBM who sold specialized hardware for expert systems.
Over time however, these expert systems were too expensive to maintain over time. Adding and removing to the already 10K+ sets of rules was difficult. It was often unclear what impact there was from changing the rules, since it could not be tested with some like unit tests in programming. As companies started abandoning expert systems, Apple and IBM saw large losses as demand for their specialized hardware plummeted in the late 1980s.
It is interesting to note how, developers of these expert systems called themselves “knowledge engineers”. This reminds me of “prompt engineers” of today. I am of the opinion that prompts will be equally difficult to maintain for the same reason as expert systems.
It is also interesting to note that expert systems continue artificial intelligence’s trend to solving narrowly scoped complex problems but do not scale generally.
2005 - Machine Learning
Somewhere around 2005, Machine Learning starts becoming the preeminent technique for artificial intelligence. Machine learning is a technique that gives the computer several training examples with labels that the computer must learn to predict. My favorite examples, is a training set of pictures of either a blueberry or a chihuahua. Machine learning can identify patterns in these pictures through several iterations of a learning algorithm and eventually get good at predicting new images (not in the training set).

Chihuahuas or muffins?
To be clear, Machine Learning algorithms have existed for a long time, e.g., Logistic Regression was developed in 1958. However, prior to 2006, the hardware available limited how many training iterations and how large the training database could be. For many problem spaces this was prohibitively expensive.
But by 2006, folks were starting to throw more and more resources at Machine Learning, and they were having a lot of success. Popular researchers and authors of the de facto artificial intelligence text book, Russel and Norvig, said, "improvement in performance obtained by increasing the size of the data set by two or three orders of magnitude outweighs any improvement that can be made by tweaking the algorithm." I find this funny because researchers in this space spent decades developing more and more complex training algorithms, e.g., support vector machines, but the most impactful thing ended up being just throwing more compute resources at the problem.
For me, this phase of artificial intelligence was heralded by the Netflix prize. This was a competition that began in 2006. In it, Netflix released a huge data set of 100 million training examples of users’ viewing history and the next movie they would watch. Each year, students were encouraged to train a machine learning model that could predict the next movie the best. I entered grad school in 2008 and the idea of this competition interested myself and many of the other research students on campus. It was part of a bigger push in AI to move away from domain specific approaches that did not scale to other domains. The techniques behind machine learning are generic, the only domain specific part is training your domain data, e.g., JPEGs of chihuahuas and blueberries, into feature vectors, i.e., numeric values that represent the images (e.g., count the number of blue pixels). All the steps after that are the same regardless of the domain you are in.
Unlike the previous breakthroughs, there is not a lot of evidence I could find of over promising with this phase of artificial intelligence. It also does not seem like we see a big disillusionment several years after. Perhaps artificial intelligence had its reputation damaged so many times there were not any people willing to come out and say that artificial general intelligence was right around the corner like they did in the past.
2017 - LLMs
This section warrants the least discussion least because it is in the news every day. In 2012, AlexNet showed that “deep learning” is successful and researchers start working on developing “large language models”. This ultimately leads to GPT-3 in 2020 which really sparked the current AI mania we are in. Whereas the 2005 phase focused on throwing lots of compute power at the size of the training data, this 2017 phase focused on throwing lots of compute power at the training iteration stage. As a result, we see that the folks who sell the specialized hardware to power this training (GPUs) are seeing a lot of success.
Parallels Today
With the exception of the Machine Learning boom, artificial intelligence breakthroughs loves to overpromise. In 1956, some researchers thought that artificial general intelligence was right around the corner. Today LLMS inspired Sam Altman to say that AGI will be developed in the next few years.
Artificial intelligence breakthroughs often solve narrow complex problems but do not scale. Early artificial intelligence relied on hard-coded heuristics tied to the problem’s domain like Chess. Expert systems relied on continually keeping up with experts’ rules but changing the corpus of rules was expensive and failed to scale over time. Today, the successful LLM applications I see require very precise and large prompts in order to succeed. These prompts remind me of the expert system rule sets. I expect them to be difficult to change reliably and to fail to scale over time too.
In the gold rush it was Levi Strauss who really got rich selling blue jeans to gold rush miners. Most of the miners struck out. Artificial intelligence has a similar history. Artificial intelligence breakthroughs reward hardware companies more often than the artificial intelligence teams. The commercial success of the artificial intelligence applications, with the exception of the machine learning phase, has not panned out.
Even though they have a problem of under delivering on its promises, artificial intelligence breakthroughs always delivers a significant change. They always automates a previously unautomated task. Just because artificial general intelligence did not come around in 1976 does not mean that the artificial game intelligences of the 1950s were a failure. IBM’s deep blue did eventually come around and beat the worlds chess experts. Netflix does successfully use machine learning to pick the next movies to suggest to us. It is inevitable that some tasks will forever be automated because of the breakthroughs in LLMs today.
When big new automations like this come out, it is important to think about the airplane pilot versus phone operators paradigm. What things will LLMs be able to replace that do not require careful human judgement, do not have severe consequences if there is a failure, and which do not require extensive training? Those things will go the way of phone operators. It doesn’t matter if the LLM is an artificial general intelligence, it just matters that it can automate that task faster or cheaper than a person can.